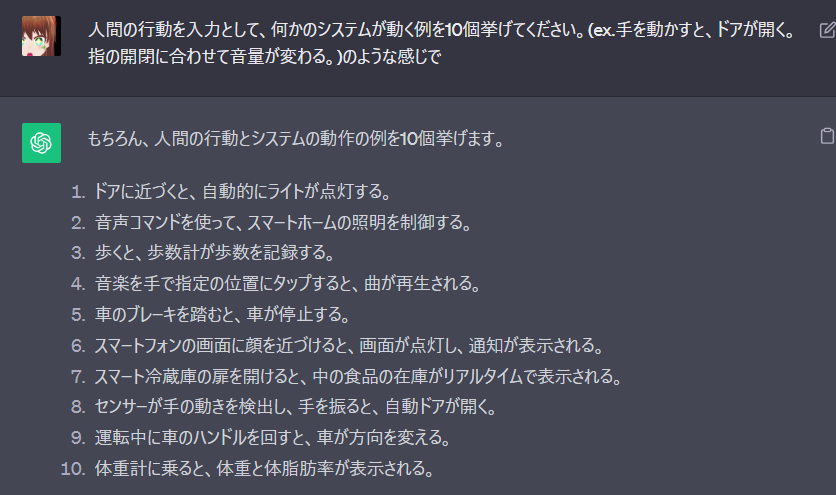
人間、辞めたくないですか? Twitter 上には「猫になりたい」「にゃーん」等と発言している人々が多く存在します。
終わることのない競争社会に疲れた人々は、動物になりヒエラルキー の外側に立つことで、社会から逃避することを夢見るようになりました。
社会にすりつぶされ、来世も期待できず、今世で猫になることを選んだヒロイン
一方、非人型の身体能力への憧れという正のモチベーションが、人々を脱人間に駆り立てることもあります。ギリシャ 神話の発明家ダイダロス は、空を飛ぶべく人工の翼を作りました。様々なファンタジー やロールプレイングゲーム においても、空や力への憧れから、人が鳥や虎やドラゴンの姿に変身する様は多く描かれています。
現実の例としては、動物のシステムや構造を解明して人工物に応用するバイオミメティクス分野や、人間の認知能力や作業能力を拡張する人間拡張分野において、動物の身体性やイメージを人間に取り込む/活用しようとする研究が行われています。
イカ ロスとダイダロス (Pyotr Ivanovich Sokolov, 1776)
現代では、VR 技術やロボット技術などを用いることで、現実の身体と異なる構造をした非人型身体を自分の身体のように操作することが可能になってきました。
学部二年の春、私は生のインターネットを求めて、VRchatの世界に降り立ちました。VR では自らの肉体を自由に選択することができます。私はTRPG プレイヤーでもあり、亜人 萌えを発症していたため、竜人 っぽいアバター を作ろうと思い立ちました。blender に100時間ほど費やして下のアバター を作成し、以降VR での身体として使用しています。
筆者のアバター
現在、私は修士 二年であり、身体の編集や非人型身体の操作をテーマに、楽しく研究を行っています。
VR 空間内で壊れたロボットになり、自らの脳内を編集して身体改造 を行うVR コンテンツ。脳内のつなぎ方により右手と左足の動作が入れ替わったりする。SIGGRAPH '23等。
本記事は、非人型アバター に関する議題や単語を整理するために書かれるものです。「非人型アバター /non-humanoid avatar 」という研究テーマは、文脈が多く、また言葉の定義もはっきりしていなかったりしているため、研究者同士においても議論が行いにくいものになっています。論文にはBackgroundやRelated Worksが書かれている為に文脈や問題をフォーカス出来ますが、Slack上や口頭でのコミュニケーションにおいてはちょくちょく認識違いが発生してしまいます。本記事では、non-humanoidに対する複数の文脈を整理し、単語の定義を確認し、研究テーマを分類し、分野を概観することを試みます。
最初に注意点をお伝えします。この記事は私の研究室とは関係がない内容であり、あくまで個人的な意見や情報を提供するものです。また、記事中には自分でも検討中の項目が多く含まれるため、間違いが存在する可能性があります。 出来るだけ情報源を貼るように努めますので、気になったトピックについては自分でも深掘ることをお勧めします。
non-humanoidの文脈
non-humanoidとは、大まかには人と外見や構造が異なる身体のことを指します。non-humanoid型身体は、主に「VR 空間上の身体」「サイボーグ(人間-機械協調体)」「(完全な)機械身体」の3通りの組成で存在します。(もちろん自然界の動物や昆虫も非人型ですが、本記事では人工物のみを扱います。)また、研究分野としては「CG・アニメーション」「バーチャルリアリティ 」「人間拡張」「(人が操作しない)ロボット」「テレイグジスタンス」などで研究されています。
主観分野マッピング
CG・アニメーション分野
この分野では、non-humanoidキャラク ターをアニメーション表現に用いることをモチベーションに色々な研究がされています。
実写版美女と野獣 のタンス
上の例のように、椅子やタンスなどの無機物をアニメーションさせたり、犬などの4足歩行動物をアニメーションさせる場面がよくあります。
KinEtre [Chen et al. 2012 UIST]の文章の初めに、以下のような一節があります。
Imagine you are asked to produce a 3D animation of a demonic armchair terrorizing an innocent desk lamp . You may think about model rigging, skeleton deformation, and keyframing.
Depending on your experience, you might imagine hours to days at the controls of Maya or Blender .
このように、non-humanoidのキャラク ターを動かすことは、その特殊な構造のために大変な作業となります。この問題へのアプローチとして、非人型の3Dモデルへのリギング(ボーンを入れること)や、リグを上手く動かす様々なアプローチが研究されています。
キャラク ターを上手く動作させるアプローチの中の一つに、操作者(通常は人間)の動作をnon-humanoidに合わせたものに変換することで、上手くアニメーションさせることを試みるものがあります。この変換の方法の一つに、関節と関節の動作を対応付けるマッピング と呼ばれるものがあり、下の章で説明します。
特にCG分野では、この人形劇的なアプローチのことをMotion Puppetryと呼ぶことが多いです(Creature Features[Seol et al. 2013 SCA]等)。日本では慶応大学の藤代先生が研究を行っていたようです。
この分野では、non-humanoid身体をVR 空間における代理の身体:アバター として用いています。私のフォーカスしている分野の一つはここです。主に自己表現や特殊な体験のためにnon-humanoidアバター が使用されます。
VR ゲームでは、自分がイカ になって街を襲うゲームなどが存在します。
Tentacular on Oculus Quest 2 | Oculus
VRSNSでは様々な人が様々なアバター を装用しています。動物や無機物など、想像力と技術力の限り、どんな存在にでも成ることが出来ます。
写真中にはウサギやパフェといった骨格からhumanoidと異なるアバター や、人型のボーンを持っているが外見だけ人間ではない亜人 やロボットっぽいアバター が見られます。この分野においては、humanoidとnon-humanoidの境目はかなり曖昧です。
VR におけるnon-humanoidアバター の研究トピックとしては、アバター の装用による認知変容(プロテウス効果)や、non-humanoidボーンを持つアバター の操作方法などがあります。後者は人間拡張分野の方で説明します。
プロテウス効果とは、用いるアバター のイメージに紐づいて、人間の認知や知覚、行動が変容するといった現象を指します。有名な研究としては「陽気な褐色肌のアバターではよりボンゴを叩くようになる 」「魅力的なアバターを使うとより社交的になる 」といった効果を示したものがあります。non-humanoidアバター においては、「ドラゴンになることで高所への恐怖が減少する 」「タコの外見を用いることで身体に柔らかさを感じる 」などといった研究があります。また、論文中でプロテウス効果と明言されてはいませんが、「サンゴ礁や牛の体験をすることで環境意識が高まる 」といった研究もあります。プロテウス効果は、人間を心理的 にサポートする手段として使える可能性があり、様々に検討が始められています。
個人的には、プロテウス効果は難しい研究テーマだと思います。
例えば、VRchatでKawaii アバター を着たときには社交的になる、というのはプロテウス効果と言えるでしょうか。外見に紐づくイメージではなく、装用者のアバター に対する態度やロールプレイへの積極的姿勢が影響を及ぼしている可能性があると考えられます。つまり、元から可愛かったり、あるいはKawaii についてのイメージを持たない老人などは、効果が低い可能性があります。プロテウス効果は、個々人のアバター に対して持つイメージに依っているのに関わらず、そのイメージに個人差がある部分には余り着目されずに、悪い結果は統計上のエラーとしてのみ処理されている気がします。このような、議論なしにマイノリティを透明化して、結果を一般化する行為は批判すべきですね。
更には、プロテウス効果には本当に身体が必要なのかという疑問もあります。TRPG では、社交性があるキャラク ターを演じている人は社交的に振舞います。この効果は三次元の体が無くても、二次元の立ち絵すら無くても、役割さえ与えられていれば観察されます。当たり前ながら、行動は期待される役割に基づいて変化します。纏まらなくなってしまいましたが、指摘したいことは以下の3点です。
1.プロテウス効果には、人がそのアバター に対して抱くイメージが異なるために、文化差や個人差があると考えられるが、その部分があまり注目されていない。
2.プロテウス効果にはアバター の外見に応じて無意識的に発現するものと、アバター の外見で期待される役割に応じて意識的に発現するものがあると考えられるが、それらが分離されていない。
3.役割に応じて発現する方のプロテウス効果は、アバター の身体が必要ない可能性がある(アバター の身体が無い場合はプロテウス効果とは言わないけれど)
個人差、役割の有無、意識・無意識、時間経過、発現の機序などを整理して議論することが出来れば博論になる気もしますが、非人型の片手間でやることではないので自分は手を引きました。
テレイグジスタンス分野
テレイグジスタンス (telexistence:遠隔存在) とは、遠隔を意味するtelあるいはteleと、存在を意味するexistenceを合わせた造語で、人間が、自分自身が現存する場所とは異なった場所に実質的に存在し、その場所で自在に行動するという人間の存在拡張の概念であり、また、それを可能とするための技術体系です。
Tachi_Lab - テレイグジスタンス
テレイグジスタンス分野では、人間の運動や感覚の入出力を計測・提示し情報技術を用いてそれを遠隔地のロボットと繋ぐことにより、人間を偏在させます。(上のサイトでは情報空間での存在もテレイグジスタンスに含むと言っていますが、肌感に合わせ、この文中では遠隔ロボットの操作のみを指します。)
ここの人間とロボットの関係のような、主従がある制御をリーダーフォロワー制御と呼びます。昔はマスタースレーブと呼んでいましたがポリコレの波によって言い換えることになったと聞きます。
テレイグジスタンスシステム「TELESAR V」 上記サイトより
この分野においても、近年遠隔地で用いるアバター ロボットとして、non-humanoidが検討され始めています。遠隔地の身体として非人型の身体を用いることで、その特殊な身体が持つ能力を活用した作業が行えるようになります。
個人的には人間拡張/human augmentation分野との重なりがあると思うのですが、下の論文中では一度もhuman augmentationという単語は出てきていませんでした.....
Piton: Investigating the Controllability of a Wearable Telexistence Robot
Iskandar et al. 2022, Sensors.
人間拡張分野
この分野は人間の色々な能力を工学的に拡張することを試みています。
"人間拡張工学の意味するところは何か、詳細は本書を通じて書き記したいと思うが、簡単に言えば人間がもともと持っている運動機能や感覚を拡張することで工学的にスーパーマン を作り出すことだ。"
「スーパーヒューマン誕生!人間はSFを超える」(稲見昌彦)
"様々な背景や価値観を持つ人々によるライフスタイルに応じた社会参画を実現するために、身体的能力、時間や距離といった制約を、身体的能力、認知能力及び知覚能力を技術的に強化することによって解決する。"
ムーンショット 目標1
この分野では様々な面白い研究が行われていますが、その中の一つに、「自らと身体形状が異なる身体を操作する」というジャンルがあります。
Metalimb
この非人型身体は、機械だったり仮想身体だったり、人間の生得的な身体とくっついていたり離れていたりします。操作方法としては上で説明した関節動作のマッピング や、IK制御、AI制御等の機械学習 的アプローチ、コマンド制御を複合することが多いです。二人羽織的に複数人の動作を融合させて一つの身体を操作する場合もあります。研究としては、操作方法の提案から実装、評価試験までを一通り行っているものが多く見られます。
個人的には、「現実の身体拡張デバイス のプロトタイプとしてバーチャルアバター を用いる」手法が好きです。
ロボット工学(人間が操作しないタイプの)
この分野については余り知らないのですが、一応non-humanoidに関連するので挙げておきます。
non-humanoid robotと検索すると、一般にはロボットアームとか謎の二頭身ロボットや動物型ロボットが出てきます。機械的 -人間的という軸があって、non-humanoidかhumanoidかは相対的なもののようです。ロボットアームとかはnon-humanoidの代表、アシモ とかペッパー君みたいなのはhumanoidの代表みたいですね。
The Social Perception of Humanoid and Non-Humanoid Robots: Effects of Gendered and Machinelike Features
この分野では、主にnon-humanoid robotとヒトとのインタラク ションとか信頼性等が研究されているようです。当然ながら、シンプルな形状のnon-humanoidロボットは、humanoidロボットよりも作るのが簡単です。
A Non-Humanoid Robotic Object for Providing a Sense Of Security
Manorらは、非人型のロボットの利点として「シンプルで手に入れやすいこと」と「機械的 な性格が明示的であり、人間の関係を置き換える他者ではなく、ツールとしてウェルビーイング を向上させることに利用できること」を挙げていました。この研究では、人の話を聞く様子のジェスチャー がsecurity(安心感)の構築に役立つという実験結果が得られていました。評価手法が面白いのでご一読ください。
接客無双(鳩胸つるん)
文脈まとめ
CG分野、バーチャルリアリティ 分野、人間拡張分野、テレイグジスタンス分野、その他ロボット分野などでnon-humanoidが扱われている
自分の身体として用いるのはバーチャルリアリティ 分野、人間拡張分野、テレイグジスタンス分野
CG分野ではキャラク ターとして用いる。自分の身体に合わせて動作させることがあるが、自分の身体の代理ではない
ロボット分野でもnon-humanoidがパートナーとか(人型である必要が無いor人型では不可能である)作業のために用いられる
研究のみならず、工業やゲーム産業、更にはVRSNSなどの文脈もある
non-humanoidに関わる研究トピックは以下のようなものが存在
操作方法、マッピング
認知変容(プロテウス効果)
新たな身体のデザイン
信頼性
non-humanoidを用いることで、人間は新たな表現能力や作業能力、体験、認知能力を獲得できる
non-humanoidアバター の分類
non-humanoidアバター の主たる構成要素は、外見・構造・操作方法の3点です。
外見
上の図のように、同じボーン構造を持ちながらも、その外見が女の子型だったりロボットだったり、太っていたり痩せていたりします。外見は頂点とその間に貼られる面(メッシュ)で作られます。頂点がボーンに紐づいて動くことにより、メッシュが変形し、アバター が全体として動作します。
構造(structure)
ボーン(bone)、ボーン構造、骨格、リグ(rig)とかとも呼ばれます。たまにmorphologyという言葉がこれを指していることもあります。
一般的なhumanoidボーン Neos wiki より
これが通常のhumanoidアバター のボーン構造です。
https://cascadeur.com/help/rig/advanced_rigging/other_topics/non_humanoid_characters
完全にhumanoidからかけ離れたボーン構造を持つこともあります。このようなボーン構造を持っているアバター は、少なくともnon-humanoid avatar と言っていいでしょう。
VRchatやUnityでは、その骨格を基準に、通常のhumanoidの骨格をもつhumanoidアバター と特殊な骨格を持つgenericアバター が分けられています。しかしながら、この分類と一般に言われるhumanoid/non-humanoidアバター の分類は必ずしも一致しません。
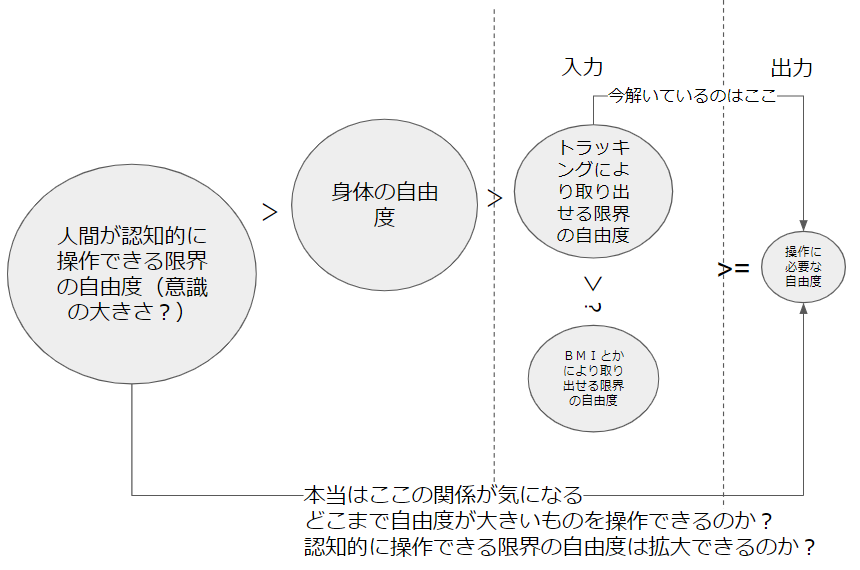
操作方法
どのようなアバター でも、それを代理身体として用いるためには、操作者の動きをトラッキング してアバター を動作させる必要があります。操作は一人称視点で行われることも3人称視点で行われることもあります。
通常のhumanoidアバター の場合は、人間の手足の位置や頭の位置とアバター のそれを1対1対応させれば済むので簡単です。
一方で、non-humanoidアバター の場合は、特殊な対応付けが必要になります。例えば天使の羽を、尻尾を、猫耳 を持つアバター のそれらの部位はどのようにして動作させれば良いのでしょうか。ケンタウロス の後ろ足をどのように動かせば良いでしょうか。自分がドラゴンになったとしたら、翼や尻尾をどのように操作するべきでしょうか。
例えば、尻尾や猫耳 や羽は前もって付けられたアニメーションに沿って動作させることができます。人間の動作をトリガーとして、あるいは人間の動作に合わせてアルゴリズム 的に動作させることもできます。しかしながら、これらの自動的な操作には主体性がなく、面白さが半減します。
もっと主体性のある方法として、人間の関節動作などの運動自由度をアバター のそれに連続的に対応付ける、モーションマッピング という方法が存在します。
モーションマッピング のイメージ。
non-humanoidアバター の曖昧性
humanoidアバター 、non-humanoidアバター として合意を得られそうなもの
左側の、vroid製アバター はhumanoidアバター として皆が認めると思われます。また、右側の猫(虎?)も皆にnon-humanoidアバター だと認められそうです。(正確には、右の猫はVR アバター として用いられてはいない単なる3DCGキャラク ターですが、分かりやすさの為に議論に含めています。以下も同様。)
しかしながら、以下のアバター たちは何方に含まれるでしょうか。
(左上)ろぽりこんちゃん
(中央上)ロボット
(右上)ストリートファイターVI
(左下)VRChat用の非人型(non-humanoid)アバターを人型リグでとりあえずなんとかした|450ch
(中央下)計数工学科
(右下)How do I Rig a Dinosaur In Blender? | Blender Tutorial | VFX_Blend - YouTube
CGソフト上でhumanoidとして扱われるか否という基準の他に、アバター の外見や、歪み具合もhumanoidアバター かnon-humanoidアバター かの判別に含まれてくると考えられます。
ろぽりこんちゃんは、通常のhumanoidリグに加え、耳や尻尾にもボーンが入っています。これはhumanoidアバター に含まれるでしょうか?少なくともUnityやVRchatでは、このようにhumanoidリグを基礎として持つアバター はhumanoidアバター として扱われいます。VR でのアバター 研究の大家Mel Slater先生はHuman Tails [Steptoe et al. 2013, IEEE ]にて、このような「アバター が基本的に人間らしい形をしておりながら、さらに付属物を含む」アバター を、extended humanoidと名付けました。この態度に本記事も賛同します。
ロボットはどうでしょうか。このように、外見は非人間であるものの、humanoidボーンを持つアバター は、ソフトウェア上ではhumanoidアバター として扱われますが、VRSNSでは人外/非人間として扱われることがあるほか、論文においてもnon-humanoidアバター として扱う例があります。上の「ドラゴンになることで高所への恐怖が減少する 」論文においても、ドラゴンアバター にはhumanoidリグが使われているように見えます(尻尾が生えている場合はextended-humanoidになります)。このように、動物や人工物を「擬人化」したアバター をhumanoidアバター に含むか、あるいは含まないかには議論の余地が残っています。擬人化されたアバター は、humanoidリグを持っているので、簡単に操作できます。
ドラゴンアバタを用いたプロテウス効果の生起による高所に対する恐怖の抑制
ここまで、大体humanoidリグが含まれていたら、humanoidアバター (もしくはextended-humanoidアバター )であるという態度を取ってきました。では、上のストリートファイターVIで作成できるキャラク ターのような、ボーンの親子関係や構成/hierarchyは通常のhumanoidリグと同じで、しかしながら歪んだ身体を持つアバター はどうでしょうか。ここまで身体比が歪んでしまうと、通常のhumanoidアバター と同様なマッピング は難しくなり、アバター として用いるためには特別なマッピング が必要になります。(実際にはこれはゲームキャラク ターなので、他のhumanoidリグと同じアニメーションを流し込まれて動作すると思われます。)
また、右下の箱のようなアバター と中央下のみがわりミズゴロウ は、Unity上でhumanoidと判定される構造を持っています。これらはhumanoidアバター に含めるべきでしょうか。結局、構造のみでhumanoid/non-humanoidを判断するのは不可能なのでしょうか。
仮にストリートファイターVIのキャラク ター群をhumanoidと認めることにしましょう。その場合、右下のティラノサウルス はhumanoidになるのでしょうか。このティラノサウルス は、ボーンの親子関係自体は、hipから伸びる二本の足とspine、spineから伸びるchest、chestから伸びるneckと二つのshoulderと、実はhumanoidリグと殆ど同じボーンの親子関係、構成を持っているようです。上で歪んでいる分にはhumanoidだと認めたので、このティラノサウルス も尻尾が付いたextended-humanoidに含まれてしまいます。うーん、非直感的でよく分からない分類になってきました......
ここまでの議論を通じて、アバター 群を外見、ボーン構成、ボーン構造の歪みの3軸くらいで分離できそうです。マッピング してみましょう。
これらを基に、どこまでがhumanoidでどこからがextended-humanoid、non-humanoidかの(直感的に納得がいく)基準を考察しましょう。
まず、ボーンの構成・ヒエラルキー にhumanoid部が含まれない「猫」と「ロボットアーム」はnon-humanoidとして良さそうです。
次に、外見が人型を保っていない(四肢が無い/動かない)「ミズゴロウ 」と「箱」もnon-humanoidとして良さそうですね。
残ったのは「ティラノ」「ストIV 」「ろぽりこん」「ロボット」「人間」です。
ここからは程度問題のように思えます。つまり、文脈によりhumanoid/extended-humanoidとして扱うか、non-humanoidとして扱うかが左右されると考えられます。再度、主観的にhumanoidかnon-humanoidかをマッピング すると以下のようになります。また、extendedであるか否かは、humanoidとnon-humanoidの中間に位置させるよりも、humanoid部分を持っているアバター をhumanoidアバター とした上でそれのサブ属性として考える方が整理できると考えられます。
テクスチャの人間らしさを重視するか、身体比を重視するか、文脈によって「ストVI」と「ロボット」は逆転する可能性があります。ですが、大体納得のいく分類が出来ました。
(ここまでの議論では、髪や衣服のリグは一旦無視して考えていました。どこからが装飾でどこからが身体化をアバター に対して定義するのは難しい。)
分類まとめ
アバター はhumanoidアバター かnon-humanoidアバター かに分かれる。humanoidアバター のサブ属性として、extendedであるか否かがある
(注:これは自論であり、extended-humanoidをnon-humanoid側に含む場合もある。特に人型-非人型の動作変換に着目する場合は。)
humanoidアバター かnon-humanoidアバター であるかを分ける基準には以下がある。
ボーンのヒエラルキー 構成(≒CGソフト、3Dソフトでhumanoidと扱うか否か)
ボーンの通常humanoidからの歪み具合(身体比・回転・相対位置・配置など)
外見(通常の人型っぽさ、人間らしさ)
humanoid/non-humanoidの別は文脈に依る
誠実な姿勢を取るためには、例えばhumanoidリグで外見のみを動物にした「擬人化」アバター をnon-humanoidアバター として扱いたい場合は、「非人型外見を持つ非人型アバター 」のように補足すべきである
non-humanoidアバター 及びextended-humanoidアバター のextended部分、あるいは非人型テレイグジスタンスアバター や第三の手のような人間拡張デバイス を自らの身体として主体性を持って操作するためには、操作者(おそらく人型)の一部あるいは全身の身体動作をnon-humanoidやextended等のそれに変換する、人型-非人型動作マッピング が必要になります。
マッピング はリマッピング とかマッチングとかリターゲティングとも呼ばれる場合もあります。
マッピング 設計の困難性は本質的に二つの要因に分かれます。
一つは、操作部位(人間側)と被操作部位(アバター 側)の構造的な類似性が小さいことです。humanoidアバター は、動作入力の関節に対し同じ関節を対応付ければ良い(例えば、右手首の動作はアバター の右手首にマッピング すればいい)ため、マッピング 設計自体は簡単です。しかしながら、non-humanoid身体に対しては、それは困難です。例えば、4足歩行の猫の右足に対して、人間の右手をマッピング したとき、猫は猫らしい動作をするでしょうか。また、蛇アバター は身体をどのように再配置すればそれらしく動かせるでしょうか。
もう一つは、そもそもアバター 身体を十全に動作させるだけの動作自由度を人間が持たないことです。天使の羽を動かすためにはどの身体部位をマッピング すれば良いでしょうか。腕をマッピング してしまうと、腕が羽と独立して動かせなくなります。肩甲骨の上下動作をマッピング すると、楽しそうですが、結局日常動作を阻害します。
これらの問題を解決するために、先行研究では、様々な手法で操作の直感性を補助し、また運動自由度を補うことで、non-humanoid身体を動作させようとしています。
異なる構造間での様々なマッピング 手法
異なる構造間でのマッピング 手法は様々に存在します。本記事で注目しているのは操作者(人型)から非人型身体構造への人型-非人型動作マッピング ですが、操作者の一部を用いて人型キャラク ターの全身を動かす、操作者の右手で左手を動かすと言ったような、人型-別の人型動作マッピング も存在します。
また、アバター の腕を人間の腕を用いて動かすような、構造が類似していたり構造が異なっていても位置的に対応付いたりする部位間でのマッピング (cis-マッピング ?)も存在すれば、人間の足を用いてアバター の腕を動かすような、動作自由度を分解して再構築するマッピング (trans-マッピング ?)も存在します。
まず、最もよく使われる手法がジョイントマッチング です。これは、関節同士で対応を取り、操作者の各関節の回転や位置をアバター のそれに変換するものです。マッピング という言葉自体がこれを指していることもあります。対応付けは基本的には一対一で行われますが、行列の掛け算のように一対多で対応させることもあります。また、線形ではない操作を行うこともあります。
FIngerWalkでは、指のトラッキング データを一旦6つほどのパラメータを持つ特徴ベクトルに落として、それを用いて適切にアニメーションを生成しています。これは、指運動とユーザーが望む全身運動の対応関係が運動の種類に大きく依存する(つまり、指で歩いている時と走っている時とで同じマッピング を用いられない)ためでした。
FingerWalking: motion editing with contact-based hand performance [Noah Lockwood and Karan Singh. 2012. EUROSCA'12: Proceedings of the 11th ACM SIGGRAPH ]
アニメーション情報に注目して動作の対応付けを行う手法もあります。Rhodinらは、人の手や顔、トラッキング スーツの点群データをターゲットの頂点変形と対応付けるアプローチを作成しました。この手法では、彼らはリギングを行っておらず、頂点を直接変形させています。他の研究では、人間の動作に合わせてボーンのアニメーションを再生・合成することも行われていました。
また、文脈は異なりますが、コマンド入力によって非人型身体や別の人型身体を操作する場合もあります(重機や格ゲーなど)。
6時間目 ~コマンドの基本~ | ストゼミ | 活動報告書 | CAPCOM:シャドルー格闘家研究所
脳波や筋電、力などの、非運動学的な値を入力に用いる場合もあります。
6th finger Projectより [Umezawa et al. 2022, Scientific Reports]
つもり制御 実はこの操縦桿は動かず、力を入力として行動意図を検出している。前田太郎先生の研究室。
また、複数人で一つの身体を動作させる場合もあります。
自在肢 [Yamamura et al. 2023, CHI] リーダーフォロワー制御で動作しており、リーダー側は別の人が動かしている。
また、少し方向性は異なりますが、前述した「擬人化」のアプローチもnon-humanoid外見を活用するために使われています。すなわち、4足歩行の猫に対してマッピング を設計する代わりに、猫を人間らしくすることにより簡単な操作を獲得します。
現場猫 - Tomcat's Toy Box - BOOTH
実験・評価系
non-humanoid(or extended-humanoid)アバター /キャラク ター/ロボット/身体は様々な観点から評価されています。
アバター に関わる評価系としては、以下のようなものがあります。
装用体験の主観的評価のアンケートによる調査
タスクパフォーマンス、運動性能の測定
装用中の行動変化の測定(プロテウス効果)
装用後の身体認知の変化の量的な調査
Skin Conductanceの変化の測定による身体化度合の測定
装用体験のインタビュー調査
アバター の身体的特性をあたかも自身の身体的特性であるかのように操作・知覚したときに感じる感覚を身体化 (Embodiment) といい、それの程度が7段階のリッカート尺度を用いたアンケートによって評価されることが多いです。他にも、プロテウス効果による主観的認知の変化や、アバター のユーザー受容性・選好などもアンケートにより調査されます。身体化や存在感の程度は、アバター に脅威提示したときの皮膚抵抗の変化を見る手法によっても調査されます。
Virtual Embodiment Questionnaire
アバター の操作性は、幾つかの運動タスクにより評価されます。非人型身体の特性を活用したタスクが設計されます。
アバター の外見のイメージに基づく行動変容も、何らかのタスクを通じて評価され、プロテウス効果の有無が調べられます。
アバター の体長や長さが人間のそれと異なる場合、アバター の装用後に身体の位置感覚が変容している可能性があるので、それが調査されることもあります。古くはRubber Hand Illusionという、ゴム手を身体化するタスクにおいて、手の位置感覚の変化(ドリフト)量が評価されていました。
また、脅威提示時の皮膚抵抗の変化を測定することにより、身体化の一要素である自己所有感を測ることがあります。所有感が高いほど、例えば腕にギロチンが落ちてきたときに、皮膚に汗を多くかくようになります。
装用体験全体をインタビューし、それから設計要素を得ようとする研究も存在します。
non-humanoidCGキャラク ターについては、マッピング 設計アルゴリズム を提案し、それで作ったアニメーションの自然さやアニメーションを作る手間などが測定されています。
non-humanoidロボットについては、人とのコミュニケーション能力や信頼性を測る研究が多いようです。
人体拡張デバイス については、設計から評価までを全部行う研究が行われています(あやふや)。
non-humanoidの価値・不全
non-humanoid身体やアバター を用いることには、これまでの通り、新しい身体を用いた表現能力・作業能力・体験を操作者に提供します。
VR 空間内で存在したい自分になる、義肢や義体 などに新たな可能性を与える、動物や非生物を理解しそれらの能力を活用することなどによって、我々は我々はより豊かで自由な人生を送ることができるようになるでしょう。
しかしながら、人型にはない不都合も起こりえます。
操作の難しさに加えて、対人コミュニケーションについても不全がおこることが想像されます。例えば、目が存在しないアバター を用いた時には、目を持ちいたコミュニケーション、例えば話す順番を察し合うことなどが不可能になります。
このアバター を使った時には、前後が分からないと言われました。
ぷにるはかわいいスライム 40話
また、人間と規格が共有しにくくなることにより、汎用性が低下することも考えられます。
非人型アバター には人型の可能性を超えた表現・作業・インタラク ション能力を人に与える可能性があるが、決してone-fits-allなアバター にはなり得なさそうです。
Ishiguro Lab. - テレノイド
関連する話題として、ロボットのコミュニケーションや信頼性について、阪大学の石黒研究室等で研究されています。人らしさには胴体や顔が必要である、その有無によって人がロボットに対してポジティブにかかわり続けるか否かが影響されるなどの結果が示されています。逆に言えば、これらの成果は非人型ロボットのコミュニケーション上での不利を表しています。非人型ロボットにコミュニケーション上の安心感を与えようとするという研究テーマは非人型ロボット界隈で盛んであるようです。
むすび
元々、我々の魂は、不当にも肉体という牢獄に囚われています。生まれつき与えられたものに満足し、それ以上のものを求めようとしないのは馬鹿馬鹿しくはないでしょうか?今こそ、自らの可能性を追求し、環境のみならず自らの在り方も変容させ、我々人類が新たな存在へと進化するべき時なのです。